背景
参考基于transformers的自然语言处理(NLP)入门
常见的NLP任务
NLP任务通常划分为4个大类:1、文本分类, 2、序列标注,3、问答任务——抽取式问答和多选问答,4、生成任务——语言模型、机器翻译和摘要生成。
- 文本分类:对单个、两个或者多段文本进行分类。举例:“这个教程真棒!”这段文本的情感倾向是正向的,“我在学习transformer”和“如何学习transformer”这两段文本是相似的。
- 序列标注:对文本序列中的token、字或者词进行分类。举例:“我在 国家图书馆 学transformer。”这段文本中的 国家图书馆 是一个地点,可以被标注出来方便机器对文本的理解。
- 问答任务——抽取式问答和多选问答:1、抽取式问答根据 问题 从一段给定的文本中找到 答案,答案必须是给定文本的一小段文字。举例:问题“小学要读多久?”和一段文本“小学教育一般是六年制。”,则答案是“六年”。2、多选式问答,从多个选项中选出一个正确答案。举例:“以下哪个模型结构在问答中效果最好?“和4个选项”A、MLP,B、cnn,C、lstm,D、transformer“,则答案选项是D。
- 生成任务——语言模型、机器翻译和摘要生成:根据已有的一段文字生成(generate)一个字通常叫做语言模型,根据一大段文字生成一小段总结性文字通常叫做摘要生成,将源语言比如中文句子翻译成目标语言比如英语通常叫做机器翻译。
Transformer的兴起
2017年,Attention Is All You Need论文首次提出了Transformer模型结构并在机器翻译任务上取得了The State of the Art(SOTA, 最好)的效果。2018年,BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding使用Transformer模型结构进行大规模语言模型(language model)预训练(Pre-train),再在多个NLP下游(downstream)任务中进行微调(Finetune),一举刷新了各大NLP任务的榜单最高分,轰动一时。2019年-2021年,研究人员将Transformer这种模型结构和预训练+微调这种训练方式相结合,提出了一系列Transformer模型结构、训练方式的改进(比如transformer-xl,XLnet,Roberta等等)。如下图所示,各类Transformer的改进不断涌现。
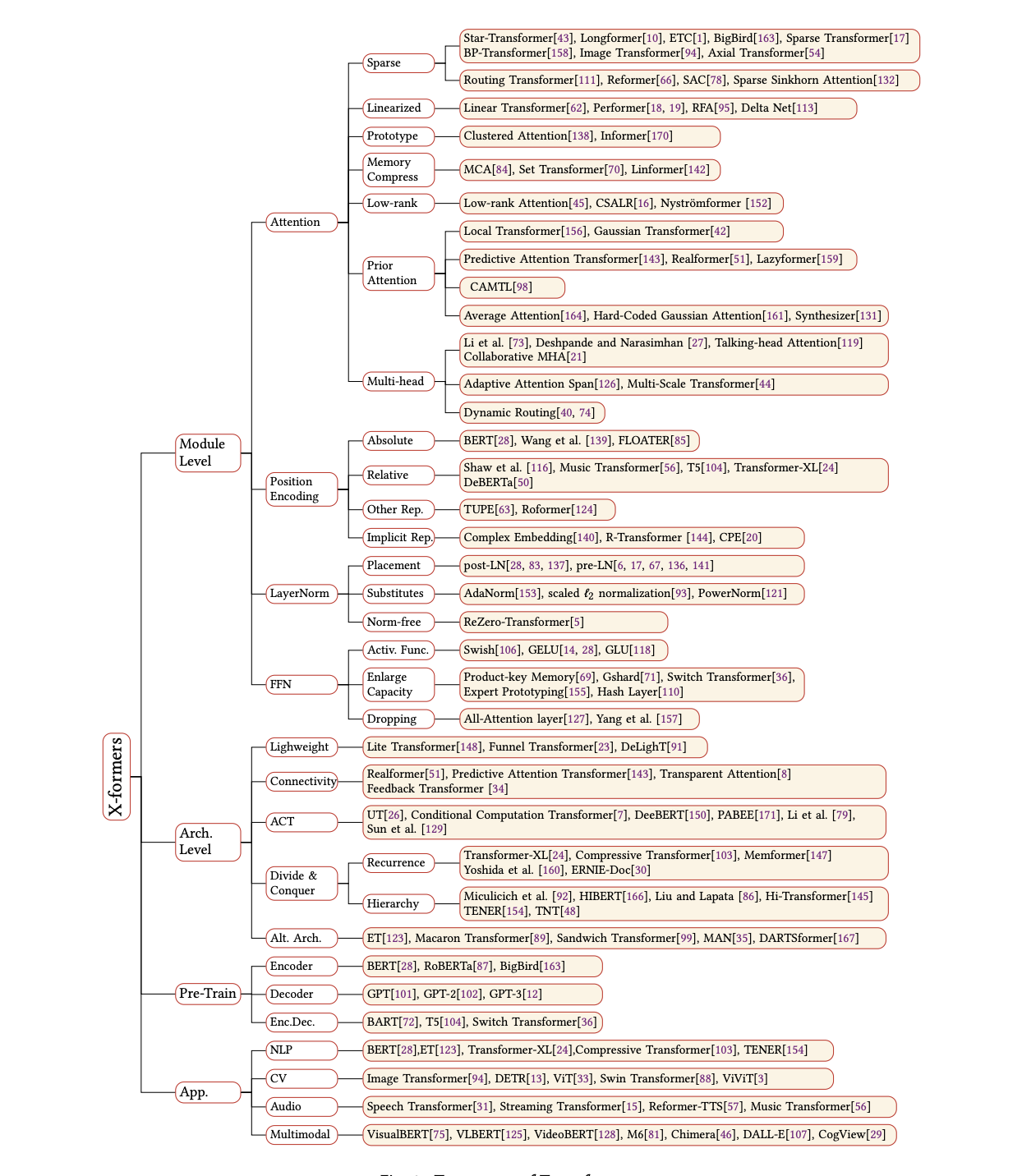 图:各类Transformer改进,来源:A Survey of Transformers
图:各类Transformer改进,来源:A Survey of Transformers
另外,由于Transformer优异的模型结构,使得其参数量可以非常庞大从而容纳更多的信息,因此Transformer模型的能力随着预训练不断提升,随着近几年计算能力的提升,越来越大的预训练模型以及效果越来越好的Transformers不断涌现,简单的统计可以从下图看出:
 图:预训练模型参数不断变大,来源Huggingface
图:预训练模型参数不断变大,来源Huggingface
尽管各类Transformer的研究非常多,总体上经典和流行的Transformer模型都可以通过HuggingFace/Transformers, 48.9k Star获得和免费使用,为初学者、研究人员提供了巨大的帮助。
图解attention
参考jay alammar的Mechanics of Seq2seq Models With Attention
- 什么是seq2seq模型?
- 基于RNN的seq2seq模型如何处理文本/长文本序列?
- seq2seq模型处理长文本序列时遇到了什么问题?
- 基于RNN的seq2seq模型如何结合attention来改善模型效果?
seq2seq
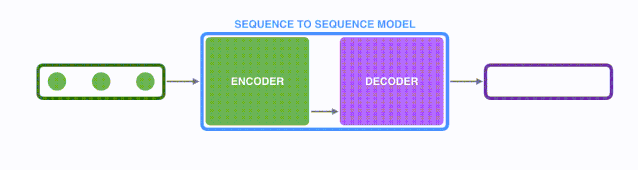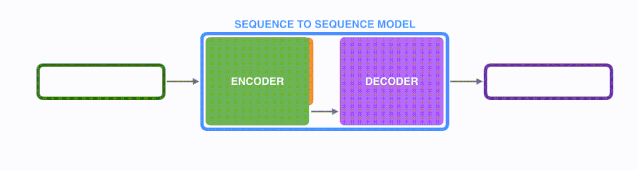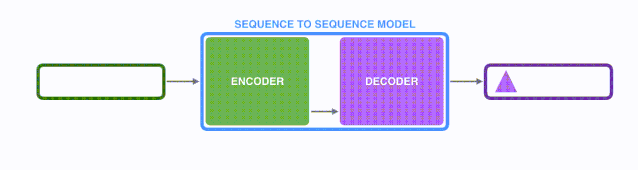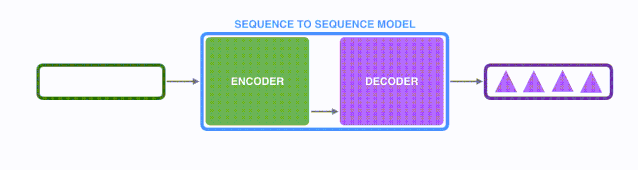 seq2seq模型由编码器(Encoder)和解码器(Decoder)组成。编码器会处理输入序列中的每个元素并获得输入信息,这些信息会被转换成为一个向量(称为context向量)。当我们处理完整个输入序列后,编码器把 context向量 发送给解码器,解码器通过context向量中的信息,逐个元素输出新的序列。
seq2seq模型由编码器(Encoder)和解码器(Decoder)组成。编码器会处理输入序列中的每个元素并获得输入信息,这些信息会被转换成为一个向量(称为context向量)。当我们处理完整个输入序列后,编码器把 context向量 发送给解码器,解码器通过context向量中的信息,逐个元素输出新的序列。
RNN是如何具体地处理输入序列的呢?
-
假设序列输入是一个句子,这个句子可以由$n$个词表示:$sentence = {w_1, w_2,…,w_n}$。
-
RNN首先将句子中的每一个词映射成为一个向量得到一个向量序列:$X = {x_1, x_2,…,x_n}$,每个单词映射得到的向量通常又叫做:word embedding。
-
然后在处理第$t \in [1,n]$个时间步的序列输入$x_t$时,RNN网络的输入和输出可以表示为:$h_{t} = RNN(x_t, h_{t-1})$
- 输入:RNN在时间步$t$的输入之一为单词$w_t$经过映射得到 的向量$x_t$。
- 输入:RNN另一个输入为上一个时间步$t-1$得到的hidden state向量$h_{t-1}$,同样是一个向量。
- 输出:RNN在时间步$t$的输出为$h_t$ hidden state向量。
动态图:
编码器逐步得到hidden state并传输最后一个hidden state给解码器。解码器在每个时间步也会得到 hidden state(隐藏层状态),而且也需要把 hidden state(隐藏层状态)从一个时间步传递到下一个时间步。
Attention
基于RNN的seq2seq模型编码器所有信息都编码到了一个context向量中,便是这类模型的瓶颈。一方面单个向量很难包含所有文本序列的信息,另一方面RNN递归地编码文本序列使得模型在处理长文本时面临非常大的挑战(比如RNN处理到第500个单词的时候,很难再包含1-499个单词中的所有信息了)。
面对以上问题,Bahdanau等2014发布的Neural Machine Translation by Jointly Learning to Align and Translate 和 Luong等2015年发布的Effective Approaches to Attention-based Neural Machine Translation 两篇论文中,提出了一种叫做注意力attetion的技术。通过attention技术,seq2seq模型极大地提高了机器翻译的质量。归其原因是:attention注意力机制,使得seq2seq模型可以有区分度、有重点地关注输入序列。
一个注意力模型与经典的seq2seq模型主要有2点不同:
-
A. 首先,编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态),如下面的动态图所示:
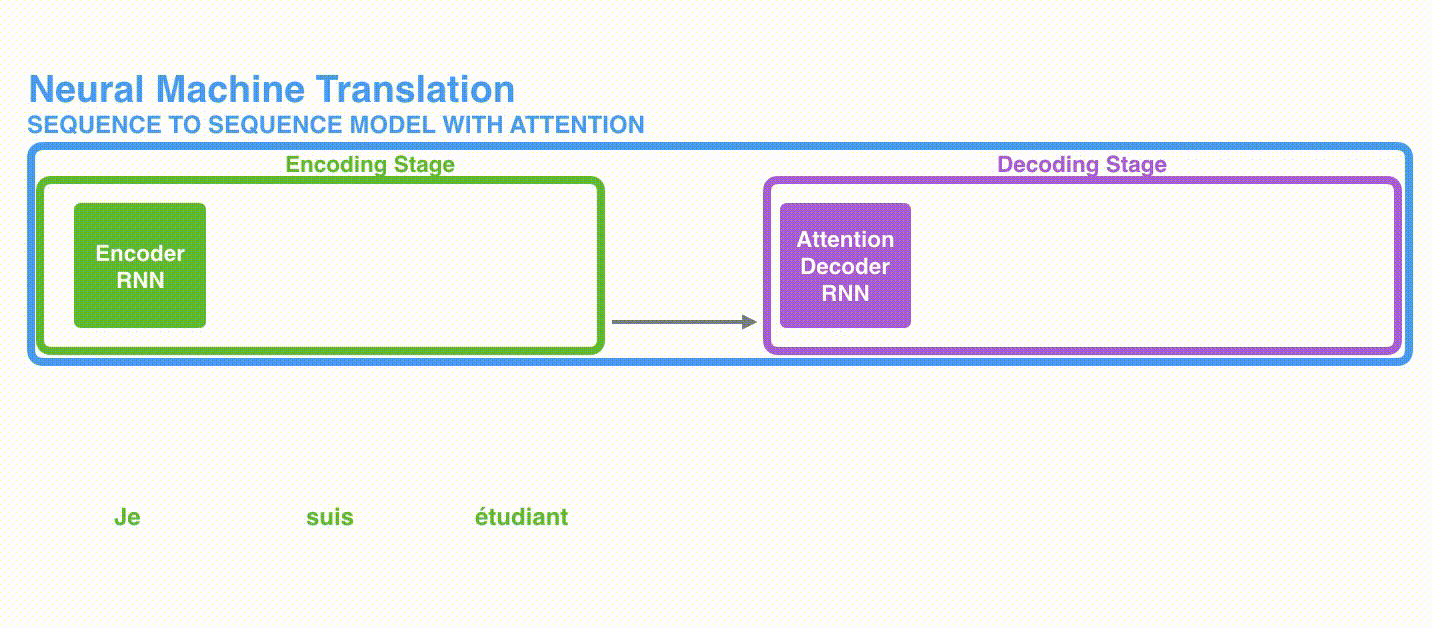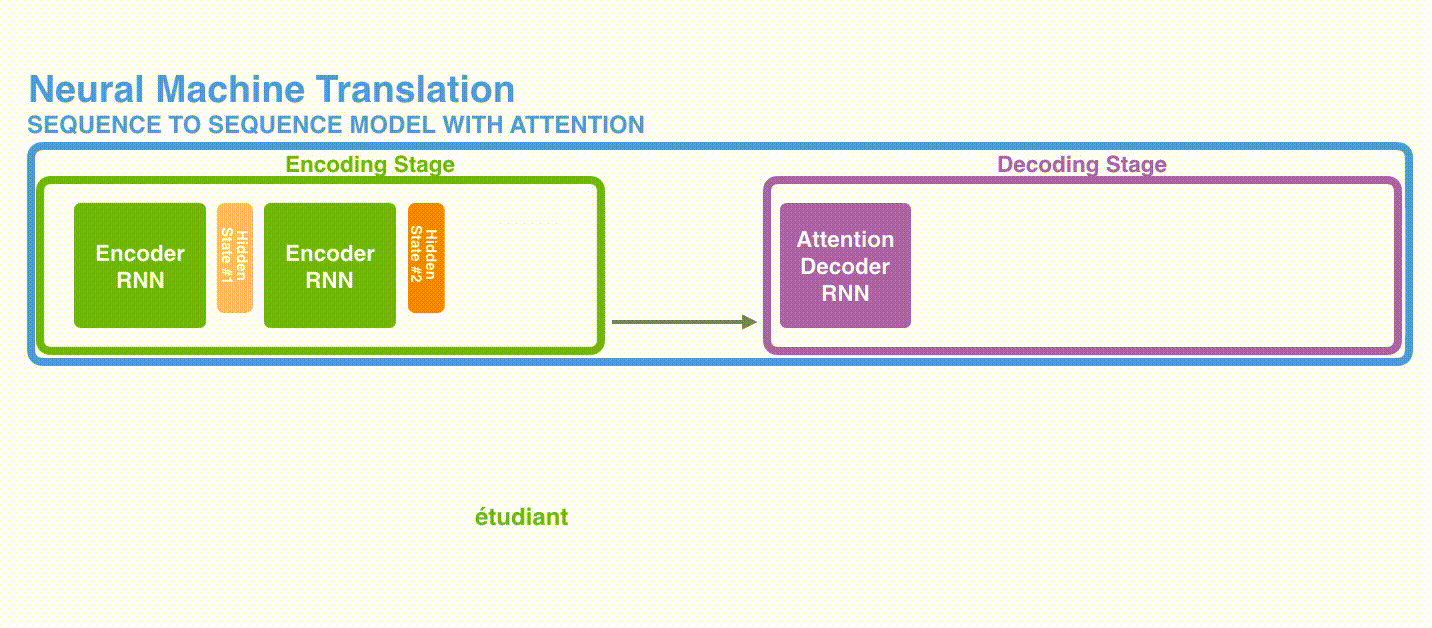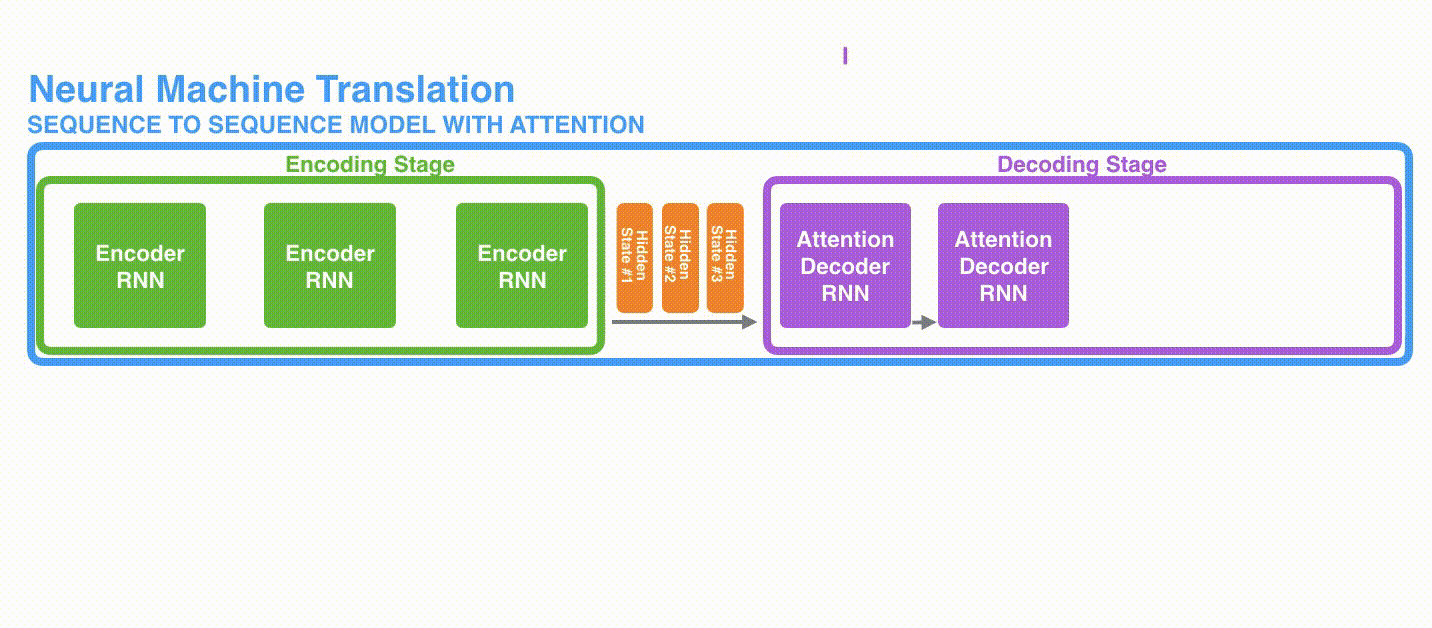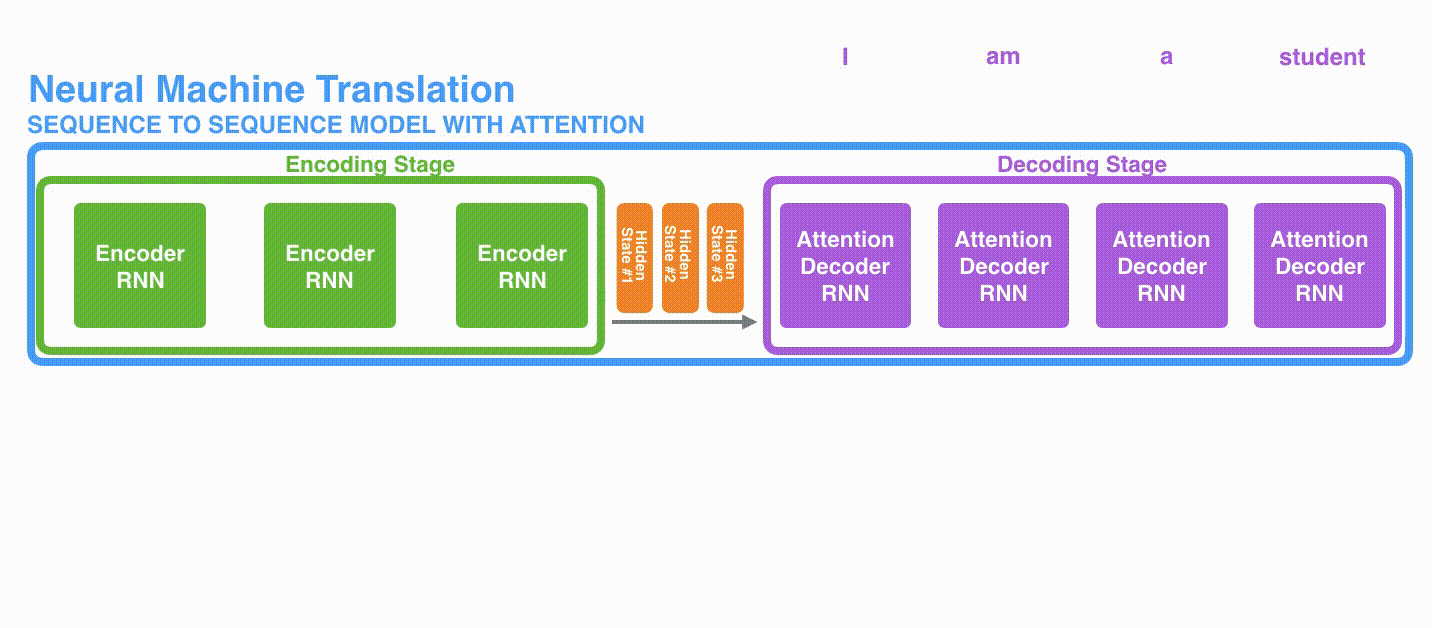 动态图: 更多的信息传递给decoder
动态图: 更多的信息传递给decoder -
B. 注意力模型的解码器在产生输出之前,做了一个额外的attention处理。如下图所示,具体为:
- 由于编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词,那么解码器要查看所有接收到的编码器的 hidden state(隐藏层状态)。
- 给每个 hidden state(隐藏层状态)计算出一个分数(我们先忽略这个分数的计算过程)。
- 所有hidden state(隐藏层状态)的分数经过softmax进行归一化。
- 将每个 hidden state(隐藏层状态)乘以所对应的分数,从而能够让高分对应的 hidden state(隐藏层状态)会被放大,而低分对应的 hidden state(隐藏层状态)会被缩小。
- 将所有hidden state根据对应分数进行加权求和,得到对应时间步的context向量。
 动态图:编码器结合attention得到context向量的5个步骤。
动态图:编码器结合attention得到context向量的5个步骤。
所以,attention可以简单理解为:一种有效的加权求和技术,其艺术在于如何获得权重。